
Le logiciel (gratuit) FreeOCR est compatible avec la plupart des scanners utilisant l'interface Twain et ouvre la majorité des fichiers PDF et des fichiers graphiques au format Tiff ou autres. Il les transforme en textes que l'on peut reprendre directement dans Microsoft Word.
Même s'il n'existe qu'en anglais, FreeOCR est très simple à utiliser. Quand on passe avec la souris sur les différents boutons visibles sur l'interface du programme, on voit apparaître une description de action que cela va activer.
Commencez par ouvrir ou scanner un document: il existe pour cela trois options qui dépendent du format de document que vous désirez lire:
Scan: numérise un document au moyen d'un scanner disposant d'une interface Twain (ce qui est actuellement le cas de la majorité des scanners vendus sur le marché).
Open: ouvre un document graphique enregistré dans un format Tiff, Jpeg, Bmp. Le logiciel permet de numériser des documents de plusieurs pages d'une seule traite.
Open PDF: ouvre un document PDF.
La reconnaissance de caractères
Sélectionnez en premier lieu la langue dans laquelle le document a été écrit.
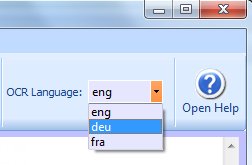
Les langues installées par défaut sont les suivantes:
Eng - Anglais
Dan - Danois
Deu - Allemand
Fin - Finnois
Fra - Français
Ita - Italien
Nld - Néerlandais
Nor - Norvégien
Pol - Polonais
Spa - Espagnol
Swe - Suédois
Cliquez sur le bouton OCR et optez pour la numérisation de la page visible dans la fenêtre de droite ou de l'ensemble du document.
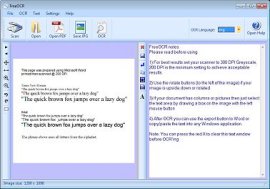
Une fois que vous aurez numérisé le document, il apparaîtra dans sa version originale dans la fenêtre de gauche et dans sa version reconnue dans la fenêtre de droite.
Vous pourrez alors soit modifier le texte mal reconnu dans la fenêtre de droite, soit effectuer un copier-coller dans votre logiciel de traitement de texte, et procéder aux corrections seulement après. Vous pouvez aussi simplement cliquer sur le bouton "Export" situé sur la barre d'outils "Text". Il est naturellement plus facile d'exporter le texte d'abord dans son logiciel de traitement de texte habituel, car c'est plus facile d'effectuer les modifications dans celui-ci que dans FreeOCR, car il propose automatiquement des changements quand il tombe sur des mots mal reconnus.